
Input
Input to object detector is a set of images for model training (mostly done on server or cloud infrastructure) and model inference (mostly done on edge device infrastructure).
Training data set of images should be
- Sizeable – larger the training data, better is detection performance, is the rule of thumb
- Diverse – it is recommended to include images featuring objects in all orientations, aspect ratios and scales that are expected in a real-world deployment scenario
- Well annotated – class labels and location bound boxes are recommended to be marked for all images in the training data set. This annotation will be used as ground truth for detecting objects in the image
Multiple open datasets of annotated images like Pascal VOC, ImageNet are publically available for training object detector models for common object classes. Deep learning based algorithms have achieved significantly improved performance using these training data sets over traditional detection methods.
Output
Object detector typically generates two-fold output
- Object class label(s) that the model is trained e.g. persons/ faces, animals, vehicles etc.
- Object locatione. corner location (x,y) and bounding box dimensions (width, height)
Mechanism
Modern object detection pipelines comprise of following functional tasks
- Recognition,e. object classification – assigning one or many class labels to objects
- Localization,e. region regression – marking object location as bounding boxes, pixel masks
- Instance Segmentation – Some methods also cover estimating the number of instances of objects for each class in scope.
There are two distinct types of object detectors in use
- Two-Stage Detectors – In the first stage, the proposal generator generates sparse region proposals and extract features from each proposal. In the second stage, for all region proposals, region classifiers predict object class labels.
Examples: R-CNN (region based convolutional neural) family including vanilla R-CNN, Fast R-CNN, Faster R-CNN
- One Stage Detectors – There are no separate proposal generator and region classifier stage. For every pixel in the image feature map, direct object categorical i.e. class label predictions, are made.
Examples: YOLO (You only look once) variants, SSD (Single Shot Detector), RetinaNet
Two-stage detectors have exhibited state-of-the-art detection performance (in terms of precision and recall of true positives) on every public benchmark.
However, these are significantly slower that one stage detector. One stage detectors are preferred in use cases requiring object detection in near real-time.
Infrastructure and Tools
For training object detection models, GPU grade compute capacity is required on the cloud/ server. The detailed specifications depend on the size of training input, the number of model parameters training batch size, among others.
For inference at edge environment with limited compute capacity available, edge porting of trained models is a key step to optimize model into a lean architecture (e.g., MobileNet, SqueezeNet) and configuration (primarily no. of model parameters, classes) to ensure optimal inference performance and speed.
Training and inference of deep learning based object detection models are executed using deep learning libraries. Tensorflow and Pytorch are popular, free, open-source libraries extensively used by the deep learning community.
Evaluating Object Detection Performance
Object detector models are measured on the following metrics.
Detection criteria
- Confidence level of predicted object class labels and localization co-ordinates
- Intersection over union or IoU, i.e. ratio of the area of intersection between predicted object localization (in terms of the bounding box or pixel mask) and ground truth object in the image (from strong annotated input) to the area of their union.
For various use case configurations, there will be recommended thresholds for these criteria. Generally, IoU threshold value is considered at 0.5 while only those top ranking n detections w.r.t confidence level are considered.
Types of detections
- IoU > threshold and predicted object class label, location matches ground truth – true positive detection
- IoU > threshold but there is no matching ground truth for predicted object class label, location – false positive
- IoU < threshold but matching ground truth is missed by detector – true negative
- IoU < threshold and there is no matching ground truth for predicted object class label, location – true negative
- This accounts for background class and is not relevant for object detection

Model Performance
The model performance is measured in terms of
- Recall – it is defined as the ratio of true positive detections to the total number of ground truth objects in the data set.
- Precision – it is defined as the ratio of true positive predictions to the total number of predictions made across the data set.
- The most used precision metric is mAP or mean average precision – average precision of object predictions across various recall levels and object classes in scope.
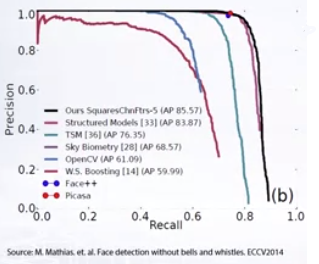
Comparing performance across models and settings
This is not as straightforward as measuring on a standalone basis as precision and recall have a strong inverse correlation among themselves.
A precision recall curve (PRC) for selected IoU values is plotted for multiple object detectors. Detectors with higher curves (more area under curve or AUC) are considered as better performing.
What’s next
In part 3, we will look at the applicability of multiple variants of deep learning based object detector to use cases across industries and diverse performance requirements of precision, accuracy and inference speed.
To conclude the series, we will look at some key emerging trends w.r.t technology maturity and business value potential that will shape object detection and computer vision discipline as a whole.










