
Introduction
A typical deep learning model development pipeline includes data acquisition, data preparation, model training, performance benchmarking of the model, optimization of the model, and finally deploying the model on the target device. Since a deep learning model learns the representation directly from the data, we can say that the more data we have, the better the performance.
Manually capturing data in such a huge amount, which includes all the variations, is a cumbersome task. Additionally, annotating such a vast amount of data is again very time-consuming and labor-intensive. To solve this problem, Nvidia has produced a simulator (Isaac Simulator) that can help an ML (Machine Learning) engineer to easily create large, annotated datasets.
To capture an image dataset from the Isaac simulator, we import a scene created using the Blender tool. After importing the scene and other required objects’ model file in the simulator, we can apply various domain randomizations, such as texture and lighting, to incorporate real-world variation in the dataset. The generated dataset is then used in training the DL model with the help of Nvidia’s provided TAO toolkit. The TAO toolkit is a one-stop solution for training, augmentation, and optimization of the model. One can export the model trained using the TAO toolkit in .trt or. plan format executable on TensorRT or Triton execution server. In this blog, we will see these tools in detail and how we can utilize them for training and deployment of a deep learning model.
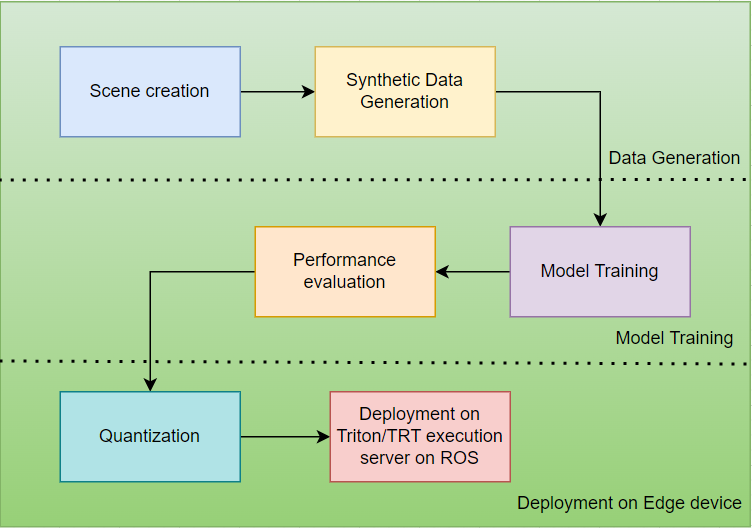
Dataset creation
We created a synthetic training dataset using Blender and the Isaac simulator. Blender is a free and open-source 3D creation suite that supports the entirety of the 3D pipeline, including modeling, rigging, animation, simulation, and rendering. The scene created using Blender is then imported into the Isaac simulator. NVIDIA Isaac Sim™ is a scalable robotics simulation application and synthetic data generation tool that provides extensive tools for synthetic data generation, such as domain randomization, ground truth labeling, segmentation, and bounding boxes.
For more details on synthetic data generation using Isaac sim please refer the following blog: From Concept to Completion: Streamlining 3D Scene Creation for Robotics with Nvidia Isaac Sim and Blender
When working with a nonlinear system like an AMR, we need to make a few changes to the Kalman Filter algorithm. To ensure that our state representation remains a Gaussian distribution after each prediction and update step, we need to linearize the motion and measurement models. This is done by using Taylor series to approximate the nonlinear models as linear models. This extension of the Kalman Filter is called the Extended Kalman Filter.
Model training using TAO Toolkit
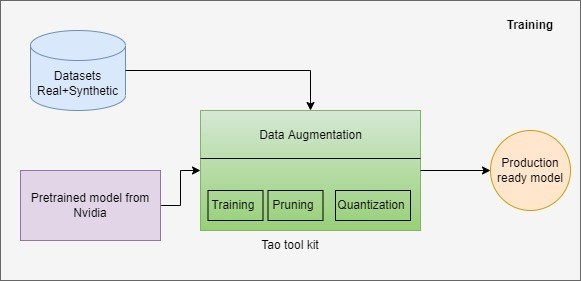
Nvidia provides a low-code solution enabling developers and enterprises to accelerate model training and optimization processes called the TAO toolkit. The TAO Toolkit helps beginners by abstracting away the complexity of AI models and deep learning frameworks. With NVIDIA TAO Toolkit, we can use the power of transfer learning and fine-tune NVIDIA pretrained models with our own data and optimize the model for inference.
The TAO toolkit provides numerous computer vision pre-trained models for object detection, image classification, segmentation, and conversation AI. Models that are generated with the TAO toolkit are completely compatible with and accelerated for TensorRT, which ensures maximum inference performance without any extra effort.
Our training pipeline exploits Nvidia TAO toolkit for efficient and swift development of the model. The workflow from synthetic data generation to deployment is shown below:
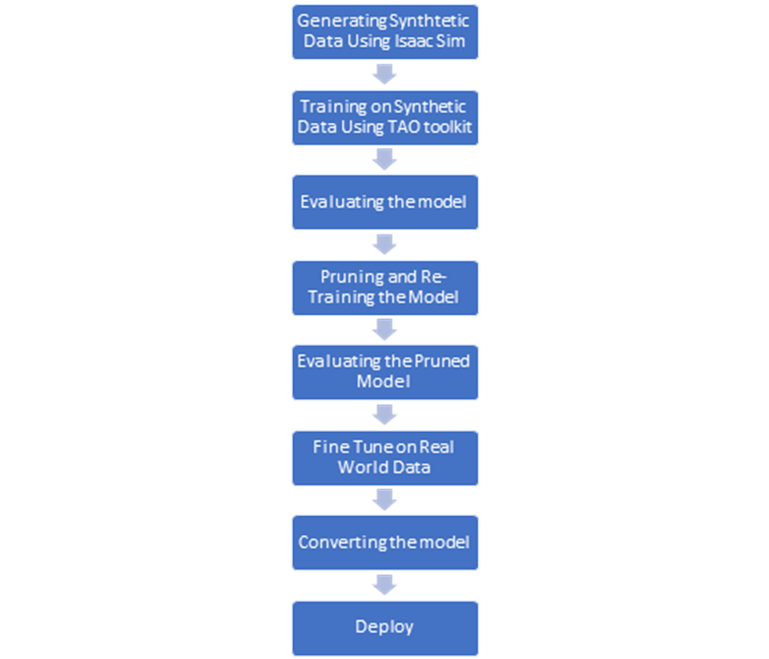
While training the model using the TAO toolkit, it is important to note that all the resources/assets which will be used throughout the TAO pipeline will be mounted onto the TAO Docker container and will be used from there. While training, environment variables are created for both the system directory path (source) and the TAO Docker container path (destination). The “mount.json” file contains the source and destination paths.
While training, it is important to keep the dimensions the same in all the spec files until the end. Changing the dimension in between will result in wrong output metrics (Precision, Recall, MIOU) and poor model performance.
For the object detection task, we selected DetectNetV2 and fine-tuned it on synthetic data generated from the Isaac simulator. The trained model file is exported and deployed on the hardware for inference. The block diagram of the training pipeline is represented below:
Deployment On Edge Devices
Gazebo is a ROS 2-enabled simulation environment that offers a lot of flexibility to test robotic systems. It allows us to introduce sensor noise, try different friction coefficients, and reduce wheel encoder accuracy, which allows us to replicate realistic scenarios that would affect the state estimation of an AMR in the real world.
To quantify the performance of sensor fusion, we can run a loop closure test, which consists of running the AMR on a randomly closed trajectory such that the AMR’s initial and final location are the same. We can then plot the state estimation done by EKF after fusing IMU and wheel encoders and compare it with state estimation done from raw wheel encoders. Ideally, we want the estimated state of our AMR to report x, y, and yaw as (0, 0, 0), respectively.
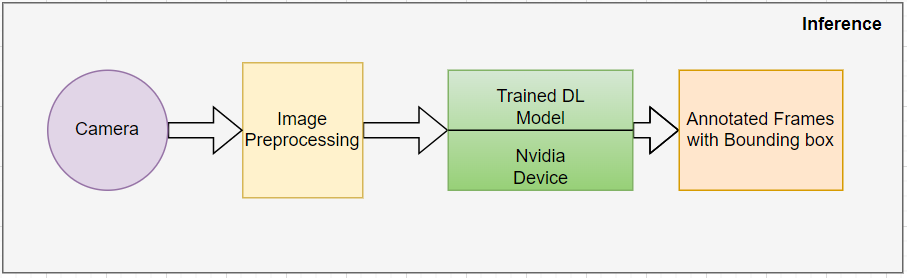
Once the model attains the desired accuracy and passes all the performance checks, it is exported into .trt or .plan file. The exported model can be deployed on Nvidia edge devices for real-time inference. The inference pipeline expects RGB images coming from the camera in real-time and applies the required preprocessing on the image to make it compatible with the model input size and achieve the desired performance/throughput. The below block diagram depicts the inference flow:
Conclusion and future scope
In this blog, we saw how we can quickly train a DL model on synthetic data and deploy it for real-time inference. We trained the model for cardboard box detection on synthetic data and achieved 90+% accuracy in the real world. In future work, we would like to experiment by mixing synthetic data with real-world data and see how it impacts the overall performance of the model.

Authors

Pallavi Pansare
Pallavi Pansare is working as Solution Engineer at eInfochips with over 4 years of expertise in fields such as signal processing, image processing, computer vision, deep learning, and machine learning. She holds a master’s degree in signal processing and is currently pursuing her Ph.D. in artificial intelligence.

ManMohan Tripathi
ManMohan Tripathi has a master’s degree in Artificial Intelligence from the University of Hyderabad. He is currently working with eInfochips Inc as a solution engineer. His area of interest includes neural network, deep learning, and computer vision algorithms.










