
System design is a crucial aspect of any project, involving stages such as designing architecture, defining interfaces, and determining resource requirements. It encompasses various elements of the project, from hardware considerations to software, data, and mechanism.
Monolith Applications
Monolith applications, also known as single-tiered applications, combine everything (UI, DAL, and so on) in the same code base or deploy them on the same node/server. While these applications are resource-efficient on a small scale, they become challenging to scale as the application grows. Monolith applications require the deployment of the entire application even for small changes, resulting in time-consuming deployments. One major disadvantage of monolith applications is scaling. Let’s understand this with an example depicted below:


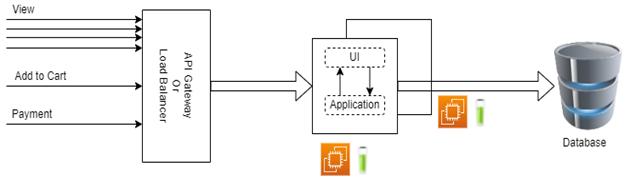
As we can see in the above example traffic increased only for view requests and CPU goes high, as traffic increase of view requests, it will impact Add to cart and Payment request’s performance as well. To prevent performance impact, we need to add a new VM instance and deploy the entire monolith application on the new VM instance. So, what’s the batter way? Let’s find out in the next section.
Microservices
Microservices involve designing applications as a collection of independent services that communicate using well-defined APIs.


As depicted in pictures above each operation is a separate microservices. This architecture will provide scalability. If there is a change in any one area of the code, we don’t need to deploy all microservices, we just need to deploy the service in which we have modifications, this will give us capabilities of reducing deployment time and modularity. As traffic for view requests increases only instance running view operations will be auto scaled and unlike in case of Monolith application, there is no performance impact on other microservices. As we are running microservices we don’t need high-end servers to run them unlike the case of Monolith applications.
We can further optimize this using serverless resources like lambda/functionApp. They will be scaled automatically; we don’t need to add them into autoscaling group to scale automatically in case of servers like EC2/Azure temporary storage.
Three-tier Architecture
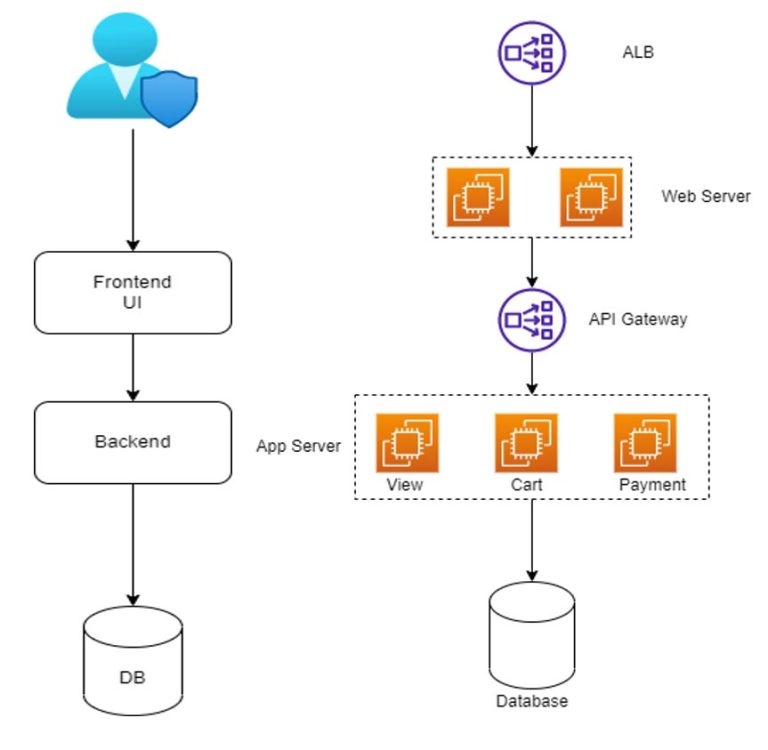
As shown in the above images, in the three-tier architecture, the system is divided into frontend (UI), backend (Application), and database services hosted on separate server nodes. This separation enhances reliability, ease of deployment, and scalability. User requests are distributed using an Elastic Load Balancer (ELB) or an API gateway. In the improved architecture shown in the second image, the web server and app server instances are placed in an auto scaling group, ensuring high availability. Still, we have some scope for improvement in the second image above. Let us first understand the limitations of architecture shown in the image above. If there is heavy traffic, there can be chances that load on either the web server or app server increases, making the application slower or in some scenarios, inaccessible. What can we do to avoid such a situation?

The answer is simple! We can put instances hosting the web server and app server in auto-scaling groups, which makes them highly available for users. When the load on an instance exceeds a defined threshold, a new instance is automatically spawned, and the load is distributed among the available instances. This universally available architecture provides a seamless experience to users, albeit at a higher cost.
Disaster Recovery
Disaster Recovery is a critical aspect of system design. The choice of mitigation actions depends on the project’s availability and consistency requirements. One solution is Active-Active, where we replicate the entire application and databases in different regions. However, there are other considerations to determine an appropriate strategy, such as Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
RPO
Consider storage as an example, where backups are scheduled every hour. In a disaster scenario illustrated below, a backup was taken at 10 am, but a disaster occurred at 10:45 am, resulting in storage failure. Consider storage as an example, where we schedule backups every hour. In a disaster scenario illustrated below, a backup was taken at 10 am, but a disaster occurred at 10:45 am, resulting in storage failure. Since the last backup was taken at 10 am, the backup storage only contains data up to that time, resulting in a loss of the last 45 minutes of data. RPO represents the maximum allowed data loss during a disaster, measured in time. To reduce RPO, more frequent backups are necessary, although complete elimination of RPO is not feasible.
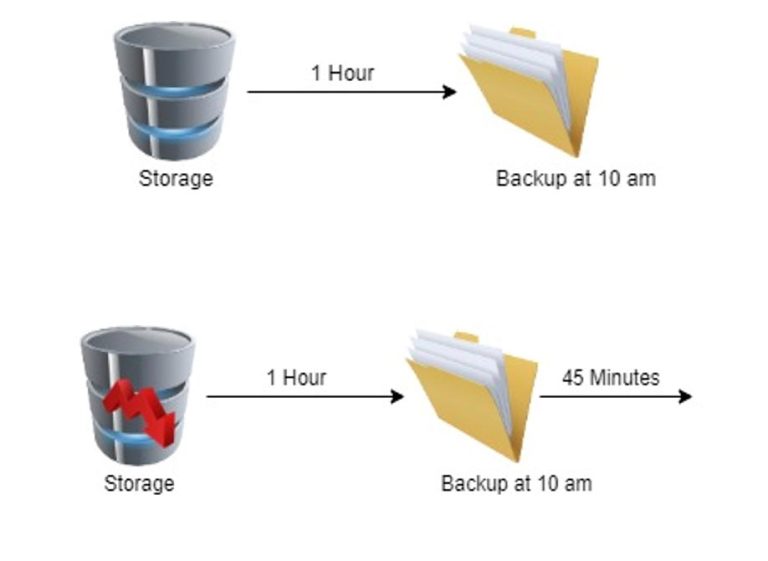
The question is how one can achieve real-time RPO without downtime for the application? For storage, we need to have real-time replication at another disaster recovery region.

RTO
RTO represents the maximum tolerable downtime during a disaster. For instance, if an application goes down at 11 am due to a disaster and comes back up at 1 am, the RTO is two hours. Let us discuss some of the strategies for disaster recovery.
Disaster Recovery Strategies
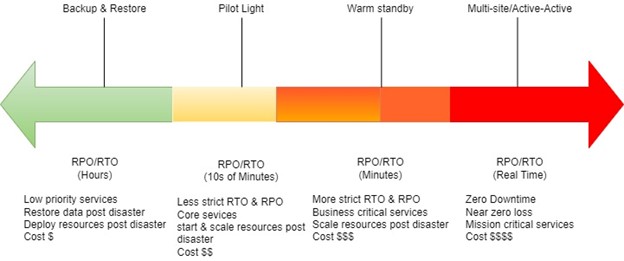
1. Backup and Restore
RPO and RTO are high compared to other strategies. The only thing that will be replicated to another region is the backup. This is the cheapest option to replicate the backup.
2. Pilot Light
RPO and RTO are less compared to backup and restore. In this strategy, the minimum core infrastructure runs in the DR region, so we can mention the application faster. For any application, data is the most important thing, hence, here data is replicated in the DR region. This is costlier than the backup and restore strategy.
3. Warm Standby
RPO and RTO are less compared to pilot light. It ensures a fully functional environment in another region, but it is not fully turned on, meaning auto scaling is not applicable here. Only single instances run for each part of an application. This is costlier than the pilot light strategy.
4. Multi-site Active/Active
In this strategy, another copy of the entire application is up and running in another DR region, hence, DB is being replicated as well as backup goes on continuously. As the entire application is running in another DR region, the cost will be the highest in this case, compared to other strategies.
Security
Now that we have designed the end-to-end system, the next step as a system designer is the security of the system.
Security is the most important aspect of system design. The first level of security can be defined at user level, which is authentication and authorization. Authentication and authorization mechanisms ensure that only valid users access the system and are granted appropriate privileges. User data security involves securing data in transit and data at rest.
For authentication, we can use B2C AD. Once the user is authenticated, the next question arises – Is the user authorized to access specific information of the system?
Authorization provides access to various levels and different areas of the application based on user or user type. Let’s understand this with a simple example, a user having admin access can access the entire application, but a user with non-admin access should have limited access to application resources and data based on the user’s access level.
Once we are done with authentication and authorization of the user, the next step is to secure data. Any system can have two types of data, data in transit and data in rest. Data in transit is the data being transferred between two systems. Data in rest represents the data in storage (DB, S3 bucket, and blob). Another level of security that we can add to protect data is firewall. Let’s understand how we can secure data using firewall and how we can secure data in transit and data in rest in the next section.
Firewall
Firewall is a system designed to restrict unauthorized access to private networks. It ensures users without access are not able to enter private networks or intranets connected to the Internet. A firewall sits between private networks and public Internet, and monitors and filters incoming and outgoing network traffic based on policies defined. An example of a system with firewalls is shown in the image below.
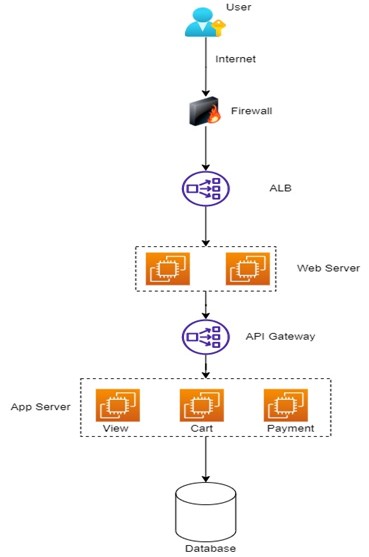
Web Application Firewall (WAF) is also a type of firewall that monitors and filters incoming traffic to web applications. It protects web applications from attacks by hackers such as DDOS. WAF blocks or rate-limits the malicious traffic coming to web applications. WAF can also be configured to prevent attacks like SQLInjection, cross site scripting and code injection.
- DDOS: In this attack, the hacker bombards the server with Internet traffic to prevent users from using the applications and sites. WAF prevents such attacks by blocking or rate-limiting incoming requests that seem malicious.
- SQL Injection: The majority of applications consist of databases. An SQL injection hacker puts an SQL query in a web form, command field or any means of input accessible to users and gets sensitive information or manipulates data in databases. WAF prevents such attacks by monitoring and filtering malicious web traffic.
- Cross site scripting: The hacker injects malicious executable scripts in applications or websites. These attacks have serious impacts, from redirecting users to malicious sites to stealing session cookies and stealing user sessions. WAF is commonly used to prevent cross site scripting.
- Code Injection: For PHP applications, a hacker can inject PHP code being executed by a PHP interpreter on the web server. WAF can filter out suspicious requests before they harm the site.
Security for data in transit
Data in transit represents data which is being transferred between two systems/applications. When data is in transit, there can be chances that it can be stolen or manipulated. It is important to have a secure channel to transfer data between two systems/applications.
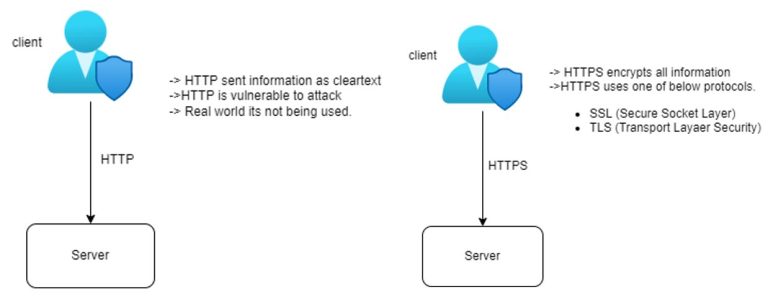
As shown in the images above, in real-world applications, HTTP is not being used due to security concerns. Real-world applications use HTTPS as it provides security of data and secured communication channel. HTTPS can be used with SSL or TLS. TLS can further be classified as MTLS (Mutual TLS). TLS is newer and faster than SSL. We would cover handshaking in SSL/TLS in another blog.In mutual TLS CA, validations happen on both the client and server sides. MTLS is generally used for B2B whereas TLS is used for web browsers.
Security for data in rest:
Data stored in DB/S3 bucket or blob needs to be secured by encrypting the data. Encryption can be done either on the client side or server side. Let’s understand both scenarios.
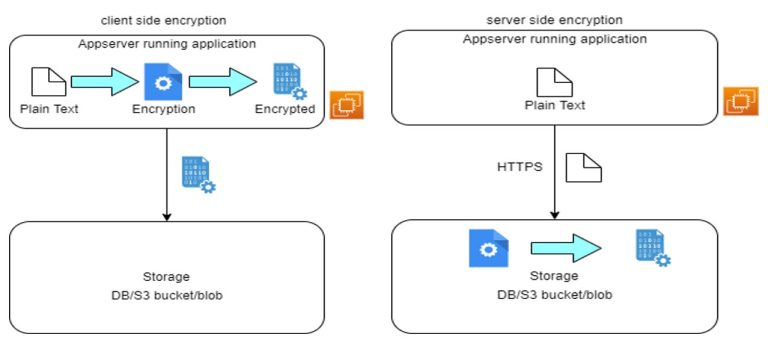
The first image shows the scenario where we perform the client-side encryption on the data before storing it. As shown in the client-side encryption, we perform encryption on the data to be stored at the app server level and then directly push encrypted data to the storage.
The second image shows the scenario where we perform the server side encryption on the data before storing it. As shown in the server side encryption, the app server sends data as it is over secured channels like https. We can configure databases in such a way that it encrypts data before storing it.
Conclusion
In conclusion, system design plays a crucial role in project success, encompassing various elements from hardware to software and data. Choosing the right architecture, such as microservices or a three-tier approach, is essential for scalability and efficiency. Disaster recovery strategies like multi-site Active/Active and security measures, including firewalls, WAFs, and encryption, are vital to safeguarding the system and ensuring its resilience against potential threats. Careful consideration of these factors ensures the development of a robust and secure system that meets user needs and withstands challenges over time.
eInfochips has collaborated with Fortune 500 companies, offering consultation and guidance in formulating optimal cloud strategies using our Cloud Assessment framework. We also create implementation roadmaps, recommending suitable service and deployment models. With our expertise in Azure and AWS platforms, we have successfully spearheaded significant cloud projects, including cloud-native design and development, transitioning from monolithic to microservices architecture, and facilitating enterprise cloud migration.









