In the previous article, we discussed text cleaning and normalization as pre-processing steps. In this article, we will convert processed text to numeric feature vectors to feed it to computers for machine learning applications.
There are three most used techniques to convert text into numeric feature vectors namely Bag of Words, tf-idf vectorization and word embedding. We will discuss the first two in this article along with python code and will have a separate article for word embedding.
Bag of Words (BoW) Vectorization
Before understanding BoW Vectorization, below are the few terms that you need to understand.
- Document: a document is a single text data point e.g. a product review
- Corpus: it a collection of all the documents
- Feature: every unique word in the corpus is a feature
Let’s say we have 2 documents as below:
- “Dog hates a cat. It loves to go out and play.”
- “Cat loves to play with a ball.”
We can build a corpus from above 2 documents just by combining it.
Corpus = “Dog hates a cat. It loves to go out and play. Cat loves to play with a ball.”
And features will be all unique words: [‘and’, ‘ball’, ‘cat’, ‘dog’, ‘go’, ‘hates’, ‘it’, ‘loves’, ‘out’, ‘play’, ‘to’, ‘with’]. We will call it a feature vector. (this will remove ‘a’ considering it a single character)
Bag of Words takes a document from corpus and converts into a numeric vector by mapping each document word to a feature vector.
Below is the visual representation of the same:
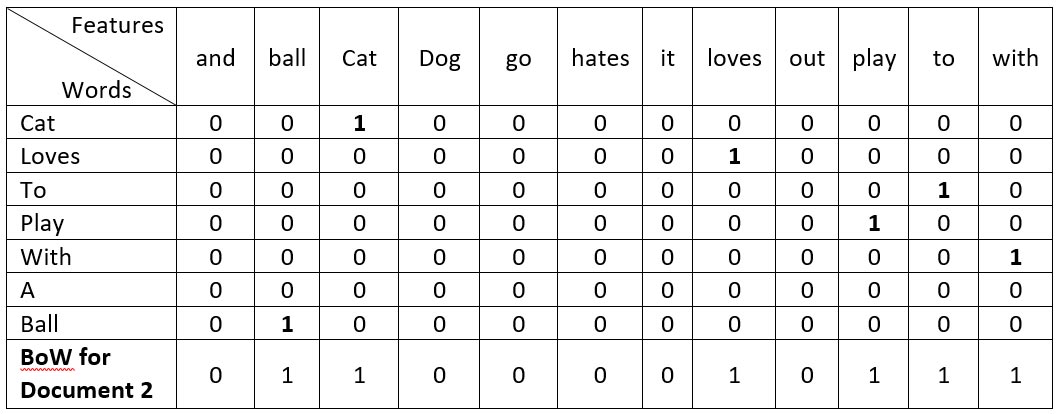
Here, each word can be represented as an array of the length of total numbers of features (words). All the values of this array will be zero apart from one position. That position representing words address inside the feature vector.
For example, in the feature vector, the word ‘cat’ is at 3rd place. Thus 3rd position’s value will be ‘1’ and everything else will be ‘0’ for the word representation of word ‘cat’ e.g. [0 1 1 0 0 0 0 1 0 1 1 1].
The final BoW representation is the sum of words feature vector.
Below is the python implementation of BoW using library Scikit-learn.
Tf-idf Vectorization
The BoW method is simple and works well, but it treats all words equally and cannot distinguish very common words or rare words. Tf-idf solves this problem of BoW Vectorization.
Term frequency-inverse document frequency (tf-idf) gives a measure that takes the importance of a word in consideration depending on how frequently it occurs in a document and a corpus.
To understand tf-idf, we will understand term frequency and inverse document frequency separately.
Term frequency gives a measure of a frequency of a word in a document. Term frequency for a word is a ratio of no. of times a word appears in a document to total no. of words in the document.
tf (‘word’) = No. times of ‘word’ appears in document / total number of words in a document
For our example, in document “Cat loves to play with a ball.” term frequency value for word cat will be:
tf(‘cat’) = 1 / 6
(note: Sentence “Cat loves to play with a ball.” has 7 total words but word ‘a’ has been ignored as discussed previously.
Inverse document frequency is a measure of the importance of the word. It measures how common a particular word is across all the document in the corpus.
It is the logarithmic ratio of no. of total documents to no. of a document with a particular word.
idf(‘word’) = log(No. of total documents / No. of a document with ‘word’ in it)
The idea is to identify how common or rare a word is. For example, a few words such as ‘is’ or ‘and’ are very common and most likely, they will be present in almost every document.
Let’s say a word ‘is’ is present in all the documents is a corpus of 1000 documents. The idf for that would be:
idf(‘is) = log (1000/1000) = log 1 = 0
Thus common words would have lesser importance. Same way, the idf(‘cat’) = 0 in our example.
The tf-idf is a multiplication of tf and idf values:
tf-idf(‘cat’ for document 2) = tf(‘cat’) * idf(‘cat’) = 1 / 6 * 0 = 0
Thus, tf-idf(‘cat’) for document 2 would be 0
Here is the python implementation of tf-idf Vectorization using Scikit-learn.
(Note: TfidfVectorizer from Scikit-learn implements bit complex formulas to implements tf-idf. Thus, the tf-idf values will be different than what we calculated.)
Both Vectorization techniques, BoW and tf-idf work well but it fails to suggest a relation between two words. E.g. king and queen are two related words but these methods fail to recreate that relation in Vectorization.
Vectorization using word embedding solves this problem. We will discuss word embedding in the next blog of this NLP blog series.
In this series, we will discuss various algorithms and method used for NLP. But NLP is not just about applying algorithms, it requires the creation of a data transformation strategy and a strong data pipeline.
We, at eInfochips, have end-to-end machine learning capabilities for NLP along with computer vision, deep learning, and anomaly detection. We help clients to bring their machine learning projects to life with 360-degree expertise from data collection to deployment. Get in touch with us to know more.









