
I don’t want to get into some cliched, worn out definition of Big Data. If you ask my opinion simply as a business professional, the only thing one needs to know is that Big Data is something that has become indispensable to the functioning of modern day enterprises no matter which vertical we talk about.
In fact, big data is one of the most trending topics on search engines today and almost every client or business partner I run into has his or her own two cents to add. I found they all voice a common concern: “Businesses today have access to the largest set of business data most of which goes unutilized, leading to potential revenue losses worth millions and billions of dollars? Why so much silence on this issue?”
![]()
I really don’t have an answer. In fact, one of the biggest concerns about Big Data is “Volume”. Businesses understand they must be able to:
1. Store large amounts of data in such a way that it will always be accessible to them.
2. Retrieve data for analysis as and when required
If we talk about data storage alone, the problem isn’t that big. Modern data storage technologies (especially due to the advent of Cloud) can be scaled to store any amount of data for as long as it’s needed. Storage data poses a challenge only when you consider the sheer amount of processing power needed (and costs) to analyze all that information. Even high-end machines can take days or months at stretch to give you tangible results. Basically, a large amount of data is useful only and only if you can leverage it for analytics and visualize the results. Otherwise, the data storage costs will keep mounting up with no profit to be made.
There’s an interesting case study of Sears in this regards. A leading retail company which operates 1,725 retail outlets worldwide, it was stuck with traditional systems built on Oracle Exadata, Teradata, SAS etc. to store and process customer activities and sales data in the form of grid storage technique which generally contains raw data. At any point of time, Sears had around 2 petabytes of data in their advanced systems, more than 90% of which was archived. It could not even include customer details even from four months back. Only 10% data was directly being used to generate BI reports simply because they had no way to cope with excess data. In other words, the topic of premature data death was not even a topic of consideration.

Hadoop was later on implemented on their system as a redressal for this problem. The retailer was in fact, one of the early first movers to Hadoop. The company removed Grid storage system entirely; and implemented Hadoop Distribution File system for storage (HDFS) as part of Hadoop ecosystem.
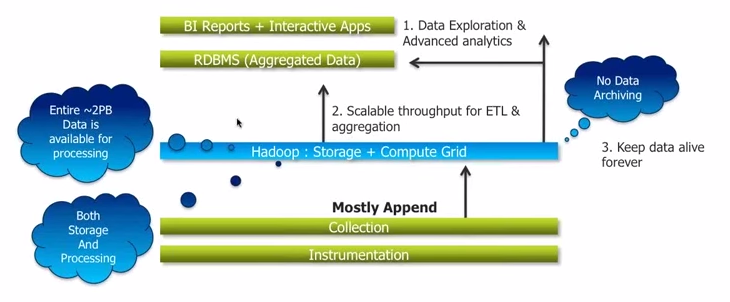
The setup facilitated the distribution of data between different data nodes on different racks & locations. In addition, the data was now being distributed as multiple commodity hardware, which eventually brought down the hardware costs. Hadoop made three replica sets to prevent data loss on commodity servers. It also removed the need of ETL compute grid as data from Hadoop storage has highly scalable for ETL and aggregation. Sears was able to keep all its data alive, eliminating the need of data archiving. The entire 2 PB data was made available for processing and analytics too.
Analytics from the complete data will always give a better picture of the scenario and strong insight about trends and customer behavior. The resulting analytics will help decision-makers to take effective decisions regarding business strategies and tend to a solid customer engagement model.
Unutilized data is a big headache for organizations and all implemented analytics need to be based on the complete data or else, one can be stuck in – The Middle of Nowhere!









